Introduction to Databases
Now that we know the basics of writing code in Python, we can start the actual work of developing our Web Stack. One of the fundamental components of the Stack is a database, which will store all of our data and allow us to access it in an efficient way.
Databases can come in a variety of structures. One of the most basic is a table, such as the ones used within Excel. Typically, each row in a table represents a piece of data, and each column represents a specific property of that data. Because the columns are hard wired into the tables, each piece of data needs to share the same set of properties, and it is very difficult to add or delete properties once a table has been started. Furthermore, to specify relationships to data in other tables you need to include columns for foreign keys, which uniquely identify rows in other tables. This can be tedious, and makes it difficult to specify arbitrary ‘many to many’ relationships.
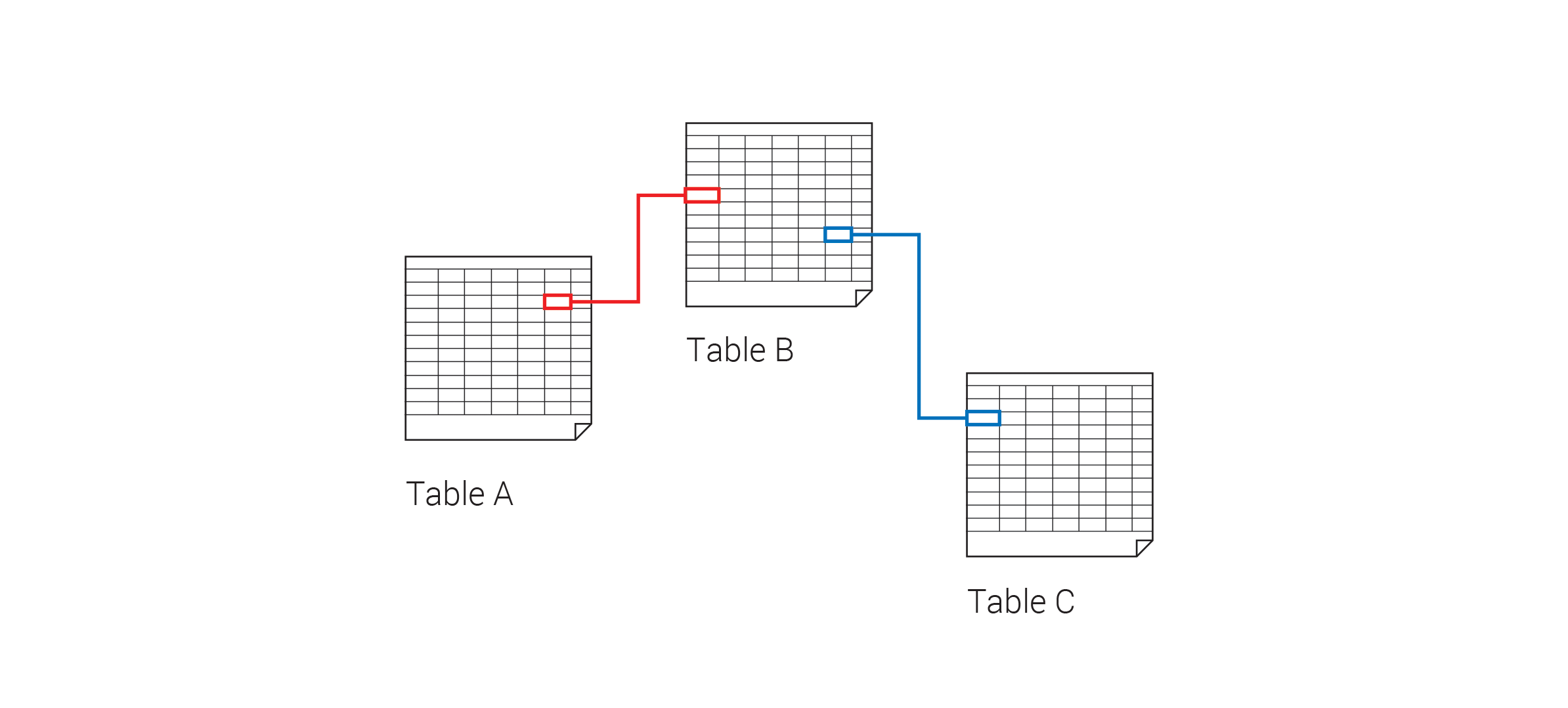 A traditional table-based relational database where connections between items can be made by specifying foreign keys
A traditional table-based relational database where connections between items can be made by specifying foreign keys
Despite these limitations, traditional tables are still widely used in data management applications today. These systems are often referred to as ‘relational databases’ due to the use of foreign keys to specify ‘relationships’ between different types of data held in different tables. For large data applications, a special language was developed called ‘Structured Query Language’ or SQL, which has commands for searching and retrieving (querying) data from the database.
To address some of the limitations of relational databases, and to accommodate the specific needs of Big Data and Cloud-based applications, several new types of databases have been developed in the last decade, loosely organized under the term NoSQL. The term NoSQL stands for ‘Not Only Structural Query Language’, implying that such systems support all the functionality of traditional SQL databases, but also add other functionality.
A very popular type of NoSQL database is known as a ‘document-oriented database’, which organizes the database as a loose collection of ‘documents’, with each piece of data represented by a single document. These documents do not necessarily have to share the same structure, allowing different pieces of data to have different properties. Because this type of database does not have to start with a predefined ‘schema’ of properties, it is often called a schema-free database. One very popular document-based database is MongoDB, which is widely used in many web applications today.
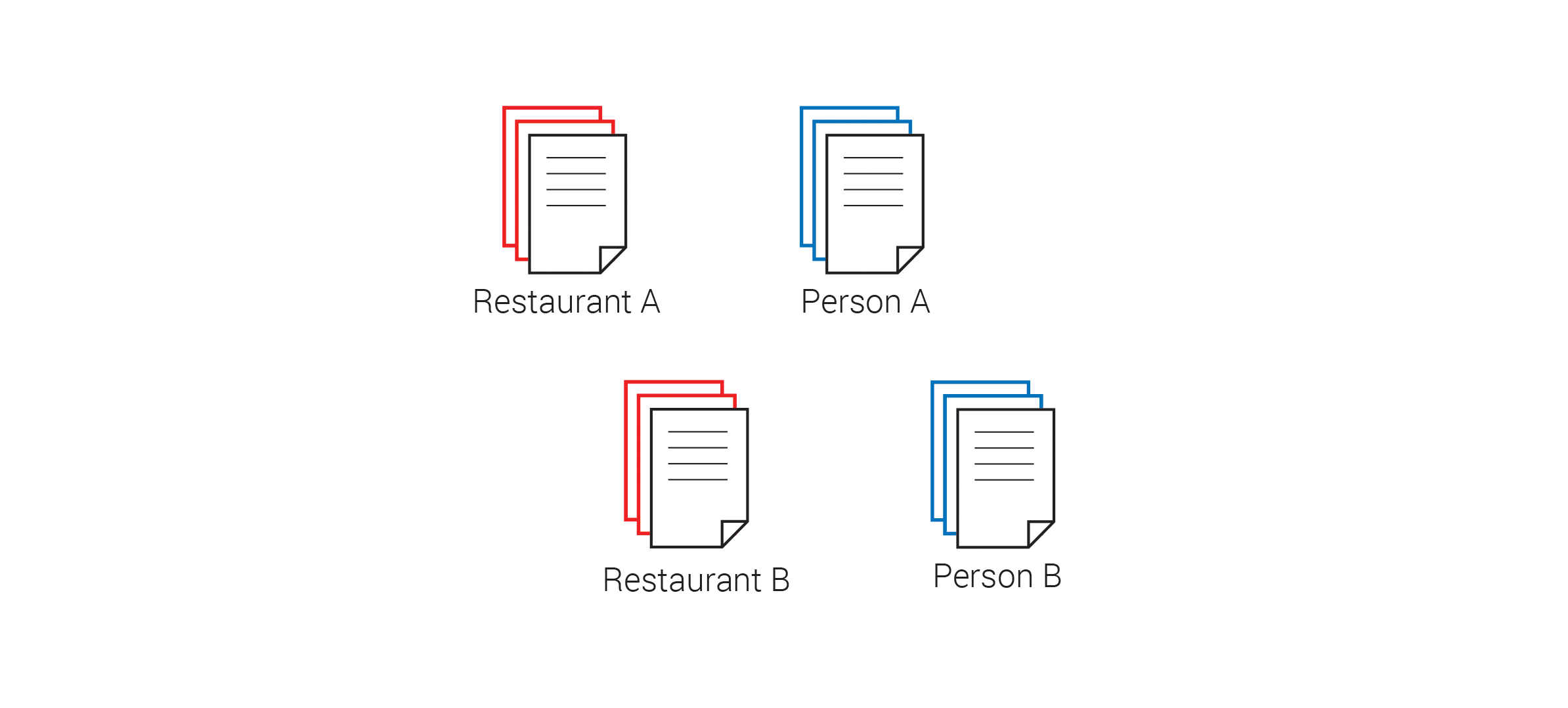 A document-oriented database where each item is stored as a separate document and can have it’s own unique properties
A document-oriented database where each item is stored as a separate document and can have it’s own unique properties
While document-oriented databases solve the problem of being restricted to a limited set of properties, they must still use a system of foreign keys to specify relationships between different pieces of data. To solve this issue, another kind of NoSQL database was developed called a ‘graph database’, which can store not only individual data points, but information about how those data relate to each other and how they interconnect. One early graph database which has become quite popular is Neo4J.
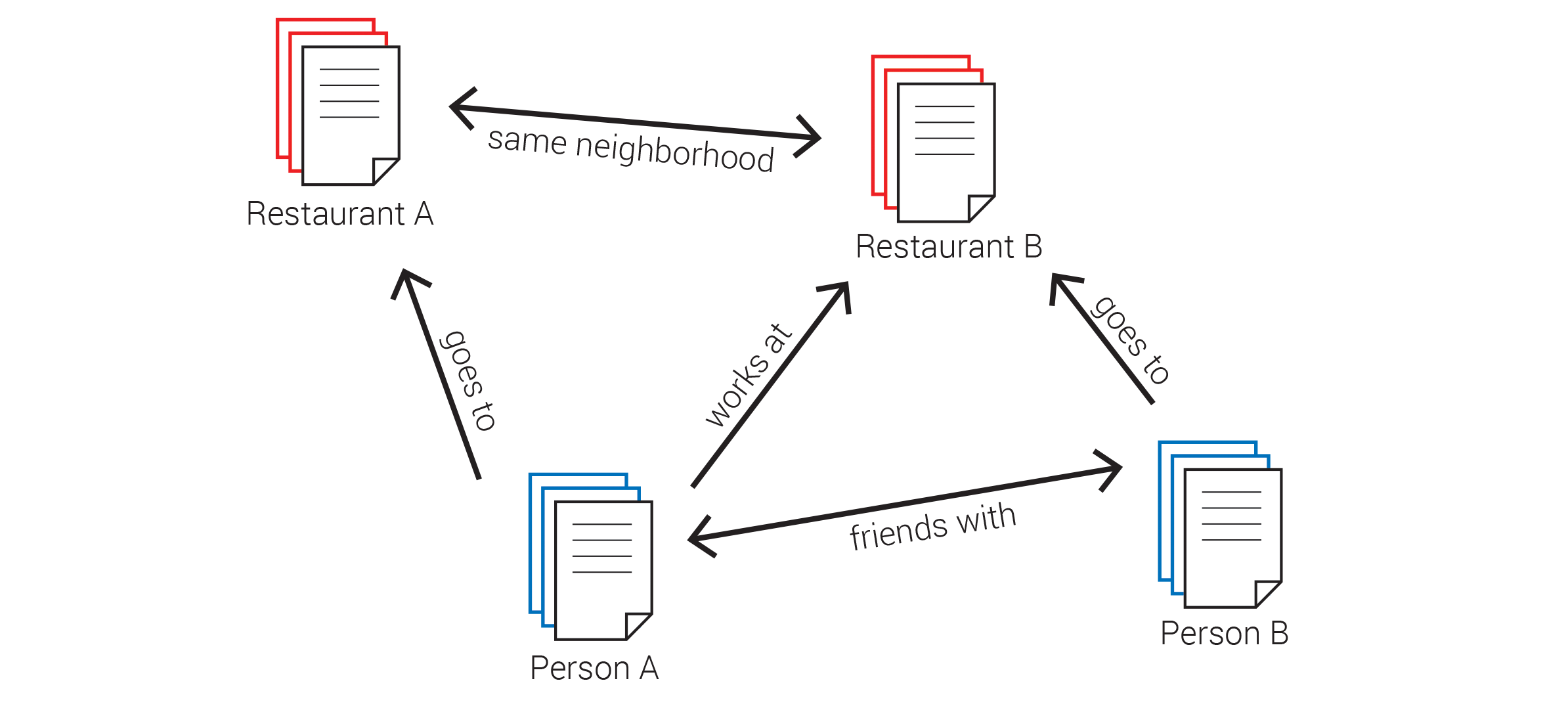 A graph database where relationships between different items can be represented as connections or ‘edges’ in a graph. These connections are stored as objects themselves and contain data about the connection as well as references to the objects they are connecting.
A graph database where relationships between different items can be represented as connections or ‘edges’ in a graph. These connections are stored as objects themselves and contain data about the connection as well as references to the objects they are connecting.
Although GIS applications have traditionally used relational, table-style databases, there are many potential advantages to using a NoSQL database. Although tables are great at storing well curated, government-provided geographic data, they have a hard time with ‘Big Data’, which is characterized by high volume, velocity, and messiness. As urban analysts begin to embrace this kind of data, they will need new tools that can handle a large steady stream of interconnected, dynamic data that does not necessarily conform to a predefined schema.
One of the data sets we will use in this class contains apartment listings for all of China, with data about when those apartments were seen online. Because each listing was accessed at different times, this kind of data could not be accommodated by a traditional table. Likewise, graph databases also have some interesting applications for urban analysis, as they are able to capture not only the static ‘stuff’ of cities, but also the dynamics behind how all that stuff interacts. Another data set we will use in the class comes from the Chinese social media network Weibo, and contains data about Weibo users and the locations they visited throughout the Pearl River Delta. Although this data could be stored in several different tables, a graph database allows us to search through the connections between places very quickly using some fundamental ideas from graph theory.
For developing our Web Stack, we will utilize one of the youngest NoSQL databases – OreintDB – which combines features of both document-oriented databases such as MongoDB and graph databases such as Neo4J. Although OrientDB is relatively new and still has some bugs, its potential as an integrated and extremely modern database system is quite exciting, and will be great to explore through the class.